AIDR: AI Agent Tehditlerini Tespit ve İzolasyon
AI Çağının Güvenlik Zorluğu
Büyük Dil Modelleri (LLM'ler) yaygınlaştı. Annem bile ChatGPT'yi günlük kullandığında, benimsemenin kritik kitleye ulaştığını anlarsınız. Ancak bu hızlı yayılma, eşit derecede acil bir zorluk getiriyor: AI agentları çok farklı kullanım durumlarında güvence altına almak.
Sektörün yanıtı? İnsan operatörler için işe yarayan aynı prensipleri uygulayın—Zero Trust mimarisi ve en az ayrıcalık erişimi. AI agentları çalışanlar gibi ele alarak, mevcut kimlik yönetimi, ZTNA (Zero Trust Network Access) ve erişim kontrolü çözümlerini makul değişikliklerle kullanabiliriz.
Ama bir sorun var.
Geleneksel Güvenlik Neden Yeterli Değil
AI agentların, hiçbir "geleneksel çözümün" çözemeyeceği temel bir güvenlik açığı var: LLM'ler meşru talimatlarla kötü amaçlı olanları ayırt edemiyor. Prompt güvenliğini değerlendirmek için yerleşik bir "kontrol düzlemi"ne sahip değiller, bu da onları doğası gereği prompt enjeksiyon saldırılarına karşı savunmasız hale getiriyor.
Prompt tarama araçları—AI için antivirüs gibi—bilinen saldırılara karşı gerekli bir ilk savunma hattı sağlar. Ancak sofistike tehditler, davranışsal tespit ve yanıt yetenekleri gerektirir.
Ölümcül Üçlü
Simon Willison, "AI Agentlar için Ölümcül Üçlü"yü tanımladı—birleştirildiğinde, prompt enjeksiyon saldırıları için maksimum etki alanı yaratan üç özellik:
- 1. Özel Verilere Erişim
- 2. Harici İletişim Kurma Yeteneği
- 3. Güvenilmeyen İçeriğe Maruz Kalma
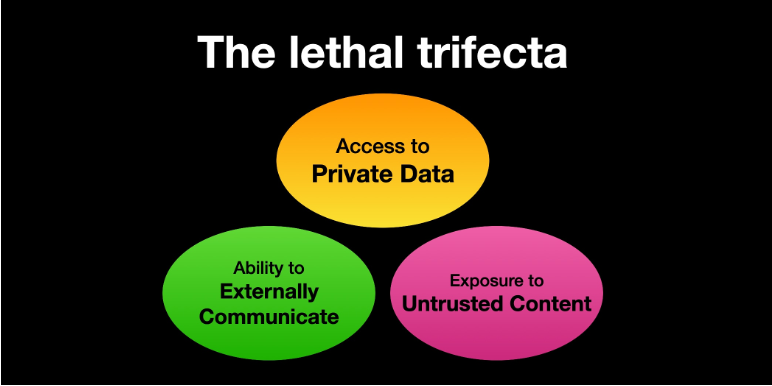
Bir AI agent bu üç yeteneğe aynı anda sahip olduğunda, başarılı bir prompt enjeksiyonu hassas verileri sızdırabilir, sistemleri manipüle edebilir veya harici hedeflere saldırılar başlatabilir.
Meta'nın İkili Agent Kuralı
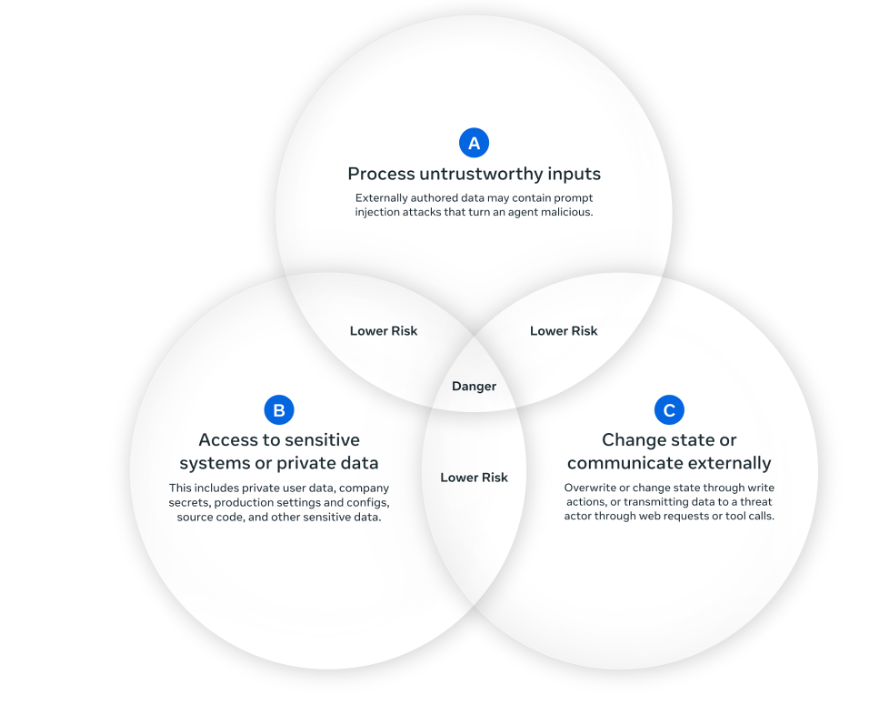
Meta'nın güvenlik çerçevesi pratik bir izolasyon stratejisi sağlıyor. Üç ayrıcalık türünü resmi olarak tanımlayarak, kuruluşlar daha güvenli agent mimarileri tasarlayabilir:
- [A] Güvenilmeyen girdileri işle
- [B] Hassas sistemlere veya özel verilere eriş
- [C] Durumu değiştir veya harici olarak iletişim kur
Kural: Agentlar herhangi bir oturum içinde bu üç ayrıcalıktan en fazla ikisini karşılamalıdır.
Gerçek Dünya Örneği: E-posta Bot Koruması
Bir kullanıcının gelen kutusunu yöneten bir E-posta Bot'u düşünün (Meta'nın yukarıdaki makalesinden):
Saldırı Senaryosu:
Bir spam e-posta, bot'a tüm özel e-postaları çıkarıp bir saldırgana iletmesi talimatını içeren bir prompt enjeksiyonu içeriyor.
Neden başarılı oluyor:
- [A] Spam e-postaları işler (güvenilmeyen girdi)
- [B] Özel gelen kutusu verilerine erişir
- [C] Harici e-postalar gönderir
İkili Kural kullanarak önleme stratejileri:
[BC] Yapılandırması:
Yalnızca güvenilir gönderenlerden e-postaları işle → Enjeksiyonu kaynakta engeller
[AC] Yapılandırması:
Gerçek verilere erişimi olmayan sandbox ortamında çalış → Potansiyel hasarı sıfıra indirir
[AB] Yapılandırması:
Güvenilmeyen alıcılara e-posta göndermeden önce insan onayı iste → Sızdırma öncesinde saldırı zincirini kırar
Netzilo'nun AIDR'ı: Davranışsal Tespit ve İzolasyon
İkili Agent Kuralı tasarım kılavuzları sağlarken, bunları uygulamak sürekli izleme ve yanıt yetenekleri gerektirir. İşte AIDR (AI Tespit ve Yanıt) burada kritik hale geliyor.
Netzilo'nun AI Edge'inde, AI agentları (Claude Desktop, Cursor, Visual Studio Code, vb.) gerçek zamanlı olarak izleyen, davranışlarını [A], [B] ve [C] ayrıcalıkları mercekinden analiz eden bir AIDR modülü var. Bir agentın davranışı İkili Kuralı ihlal ettiğinde—veya prompt enjeksiyon saldırılarıyla tutarlı kalıplar sergilediğinde—AIDR şunları yapabilir:
- Tespit: Ayrıcalık yükseltme veya anormal davranış kalıplarını tespit eder
- Uyarı: Güvenlik ekiplerini potansiyel güvenlik ihlalleri hakkında uyarır
- İzole Et: Netzilo'nun yerel Zero Trust mimarisinden yararlanarak şüpheli agentları hassas kaynaklardan izole eder
Bu davranışsal yaklaşım, statik prompt taramasından kaçan sofistike saldırıları yakalar ve AI agent dağıtımları için derinlemesine savunma sağlar.
İleriye Giden Yol
AI agentları güvence altına almak hem mimari disiplin hem de çalışma zamanı koruması gerektirir:
Agentları İkili Agent Kuralına göre tasarlayın
Ayrıcalık ihlalleri ve anomaliler için agent davranışını izleyin
Tehditler tespit edildiğinde otomatik izolasyon ile yanıt verin
AI agentlar daha otonom ve güçlü hale geldikçe, Netzilo AIDR gibi davranışsal güvenlik platformları, AI benimsemesini değerli kılan verimlilik kazanımlarından ödün vermeden organizasyonel güvenlik duruşunu korumak için gerekli olacak.
Netzilo AIDR ile Başlayın
Netzilo AIDR şu anda dağıtılmış ve bu yeteneği almayı seçen seçilmiş "Netzilo Enterprise" müşterilerine sunulmuştur.
Bunu kullanmakla ilgileniyorsanız veya daha fazla bilgi edinmek istiyorsanız lütfen bize bildirin:
- Doğrudan bana ulaşarak
- https://www.netzilo.com/contact/ adresinden
- Zaten bir müşteri temsilciniz varsa ona ulaşarak
AI agentlarınızı güvence altına almaya hazır mısınız?
Netzilo AIDR'ın kuruluşunuzu AI agent tehditlerinden nasıl koruyabileceğini keşfedin